
Introduction
AI inference systems are designed to process user requests as efficiently as possible. Whether powering a chat-bot, image recognition application, recommendation engine, or large language model (LLM), the goal is to deliver accurate results with minimal delay. While hardware capabilities and model optimization receive much of the attention, request arrival patterns are another critical factor that can significantly influence system performance.
The timing, frequency, and volume of incoming requests directly affect how efficiently an inference server operates. Understanding these patterns can help organizations optimize resource utilization, reduce latency, and improve scalability.
Understanding Request Arrival Patterns
A request arrival pattern refers to the way inference requests enter an AI system over time. In real-world environments, traffic is rarely constant. User activity fluctuates throughout the day, creating varying levels of demand.
Some applications experience a steady stream of requests, while others encounter sudden bursts of traffic due to marketing campaigns, product launches, breaking news, or viral content. Because AI infrastructure must respond to these changing conditions, request arrival patterns become an important consideration in system design.
Common Types of Traffic Patterns
Different applications generate different traffic behaviors.
1. Steady Traffic
In this scenario, requests arrive at a relatively constant rate. Enterprise systems and internal business applications often experience predictable workloads that make capacity planning easier.
2. Burst Traffic
Burst traffic occurs when a large number of requests arrive within a short period. Consumer-facing AI applications frequently encounter this pattern during peak usage hours.
3. Variable Traffic
Many AI services experience fluctuating demand throughout the day. Traffic may rise during business hours and decrease overnight.
4. Event-Driven Traffic
Major events can trigger sudden spikes in activity. Sports events, product announcements, and social media trends often create temporary surges that challenge inference infrastructure.
How Arrival Patterns Affect System Performance
Request arrival behavior influences several key performance metrics.
1. Queue Length
When requests arrive faster than the system can process them, they begin accumulating in queues. Longer queues increase waiting times and place additional pressure on computational resources.
2. Response Time
As queue lengths grow, users must wait longer for results. Even highly optimized models can experience increased response times if incoming traffic exceeds processing capacity.
3. Resource Utilization
Request patterns also affect hardware efficiency. During periods of low demand, GPUs and CPUs may remain underutilized. During traffic spikes, the same resources may operate near maximum capacity.
Maintaining balanced utilization is essential for cost-effective AI serving.
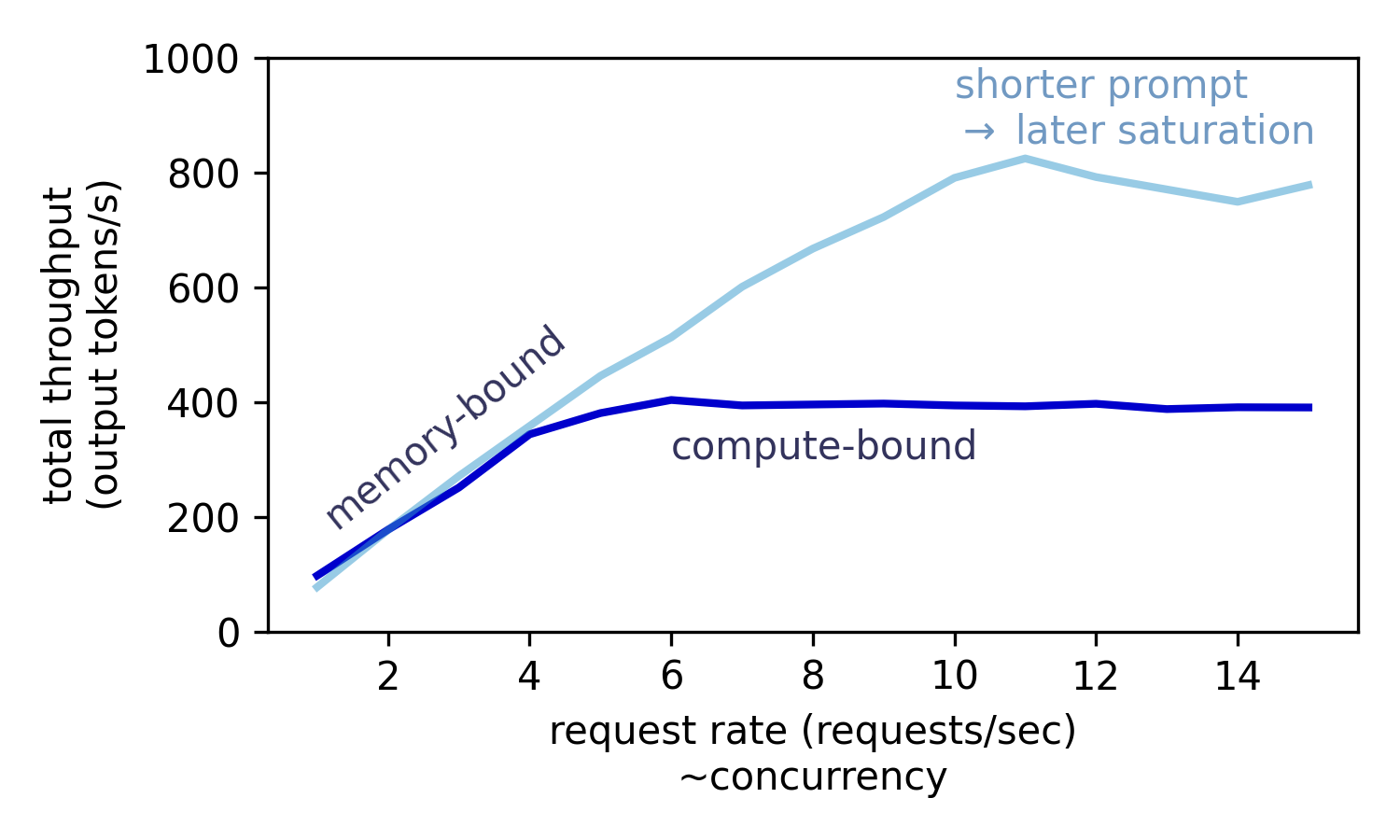
The Relationship Between Traffic and Batching
Batching allows inference systems to process multiple requests simultaneously, improving throughput and hardware utilization. However, batching efficiency depends heavily on arrival patterns. When requests arrive continuously, servers can easily form larger batches, maximizing GPU performance. In contrast, sparse or unpredictable traffic may result in smaller batches and reduced efficiency.
This is why modern AI serving platforms often use adaptive batching strategies that adjust to current traffic conditions.
Conclusion
Request arrival patterns are a fundamental factor in AI inference performance. They influence latency, throughput, batching efficiency, and resource utilization, often determining how well an AI service performs under real-world conditions.
By understanding traffic behavior and implementing adaptive serving strategies, organizations can build AI systems that remain responsive, scalable, and efficient even as demand changes over time.


